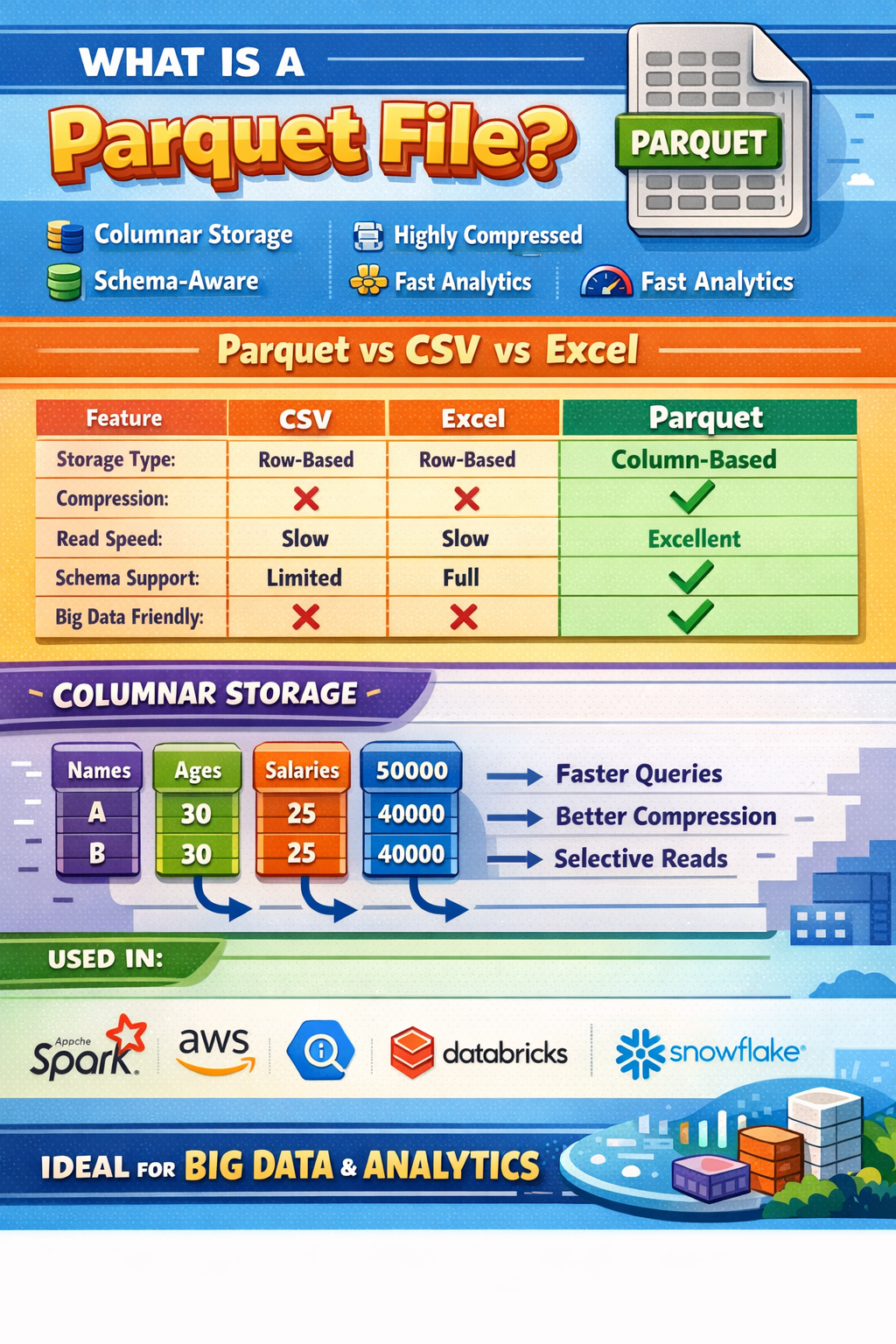
A Parquet file is a columnar storage file format widely used in Data Engineering, Data Science, and Big Data systems.
Apache Parquet is:
A binary
Column-oriented
Highly compressed
Schema-aware file format
Designed for fast analytics and efficient storage.
| Feature | CSV | Excel | Parquet |
|---|---|---|---|
| Storage type | Row-based | Row-based | Column-based |
| Compression | ❌ | ❌ | ✅ Excellent |
| Read speed | Slow | Slow | ⚡ Very fast |
| Schema support | ❌ | Partial | ✅ Full |
| Big data support | ❌ | ❌ | ✅ Designed for it |
| Cloud friendly | ❌ | ❌ | ✅ |
Instead of storing data row by row, Parquet stores data column by column.
Example:
Name | Age | Salary
A | 30 | 50000
B | 25 | 40000
Parquet stores:
Names → A, B
Ages → 30, 25
Salary → 50000, 40000
✅ Faster queries
✅ Better compression
✅ Read only required columns
Apache Spark
Hadoop
AWS Athena
Google BigQuery
Databricks
Snowflake
Pandas / PyArrow
Perfect for:
Analytics
Machine Learning pipelines
Data lakes
ETL pipelines
pip install pandas pyarrow fastparquet
import pandas as pd
df = pd.DataFrame({
"name": ["A", "B"],
"age": [30, 25],
"salary": [50000, 40000]
})
df.to_parquet("data.parquet")
df = pd.read_parquet("data.parquet")
print(df)
Parquet → More popular, cross-platform
ORC → Slightly faster in Hive ecosystems
❌ Small files
❌ Frequently updated row-level data
❌ Simple human-readable storage
Parquet = best format for storing large analytical data efficiently
 Continue With Google
Continue With Google  Data Science
Data Science

