A vector index is a data structure that enables fast similarity search over high-dimensional vectors (embeddings).
In RAG systems, indexes decide:
⚡ How fast retrieval is
🎯 How accurate the context is
📈 How well the system scales
Embeddings give meaning — indexes give speed.
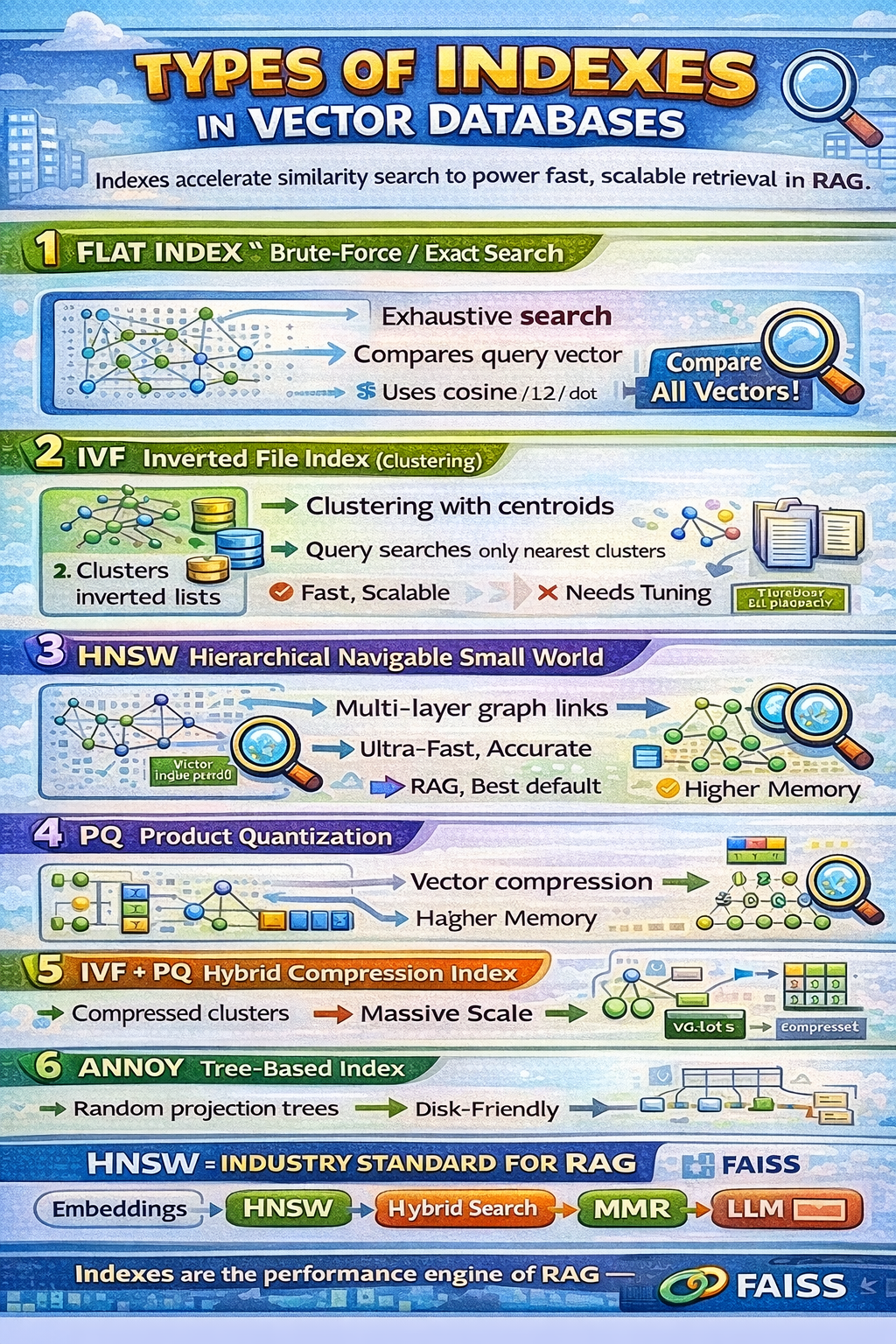
Stores all vectors in raw form
Compares query vector with every vector
Uses cosine / L2 / dot product
100% accurate
No approximation
Simple
Extremely slow at scale
O(N) complexity
Small datasets (<50k vectors)
Benchmarking
Validation
FAISS IndexFlatL2
Testing RAG pipelines
Clusters vectors into centroids
Each centroid → inverted list
Query searches only nearest clusters
📚 Library shelves — you search only the relevant shelf, not the entire library.
Much faster than flat
Scales to millions
Approximate
Needs tuning (nlist, nprobe)
FAISS (IVF)
Milvus
Large-scale RAG
Builds a multi-layer graph
Top layers = fast jumps
Bottom layer = accurate neighbors
🛣️ Google Maps: highways → city roads → local streets
Extremely fast
High accuracy
Best for real-time RAG
Higher memory usage
Slower index build
FAISS
Qdrant
Weaviate
Pinecone (conceptually)
👉 Default choice for production RAG
Splits vectors into sub-vectors
Each sub-vector quantized
Stores compressed representation
Reduce memory footprint drastically
Very memory efficient
Enables billion-scale search
Loses accuracy
Approximate distances
FAISS PQ
Mobile / edge AI
Huge corpora
IVF narrows search space
PQ compresses vectors inside clusters
Massive scale
Low memory
Fast
Lower accuracy than HNSW
FAISS (IVFPQ)
Very large enterprise datasets
Builds multiple random projection trees
Search across trees
Simple
Disk-friendly
Less accurate than HNSW
Static (no frequent updates)
Spotify recommendations
Lightweight systems
Combines partitioning + quantization
Optimized for TPUs / GPUs
Extremely fast at scale
Complex
Less flexible
Google internal systems
Large ML pipelines
| Index Type | Accuracy | Speed | Scale | Best Use |
|---|---|---|---|---|
| Flat | ⭐⭐⭐⭐⭐ | ❌ | ❌ | Small data |
| IVF | ⭐⭐⭐⭐ | ⚡⚡ | ✅ | Large corpora |
| HNSW | ⭐⭐⭐⭐⭐ | ⚡⚡⚡ | ✅✅ | RAG (Best) |
| PQ | ⭐⭐ | ⚡⚡ | ✅✅ | Memory-limited |
| IVFPQ | ⭐⭐⭐ | ⚡⚡⚡ | ✅✅✅ | Massive scale |
| Annoy | ⭐⭐⭐ | ⚡ | ⚠️ | Lightweight |
| ScaNN | ⭐⭐⭐⭐ | ⚡⚡⚡ | ✅✅ | Google-scale |
Embeddings → HNSW → Hybrid Search → MMR → LLM
🔹 <100k vectors → Flat / HNSW
🔹 100k–10M → HNSW
🔹 10M+ → IVF + PQ
Vector indexes are the performance engine of RAG — and HNSW is the industry’s most trusted index for fast, accurate semantic retrieval.
I
 Continue With Google
Continue With Google  Data Science
Data Science

