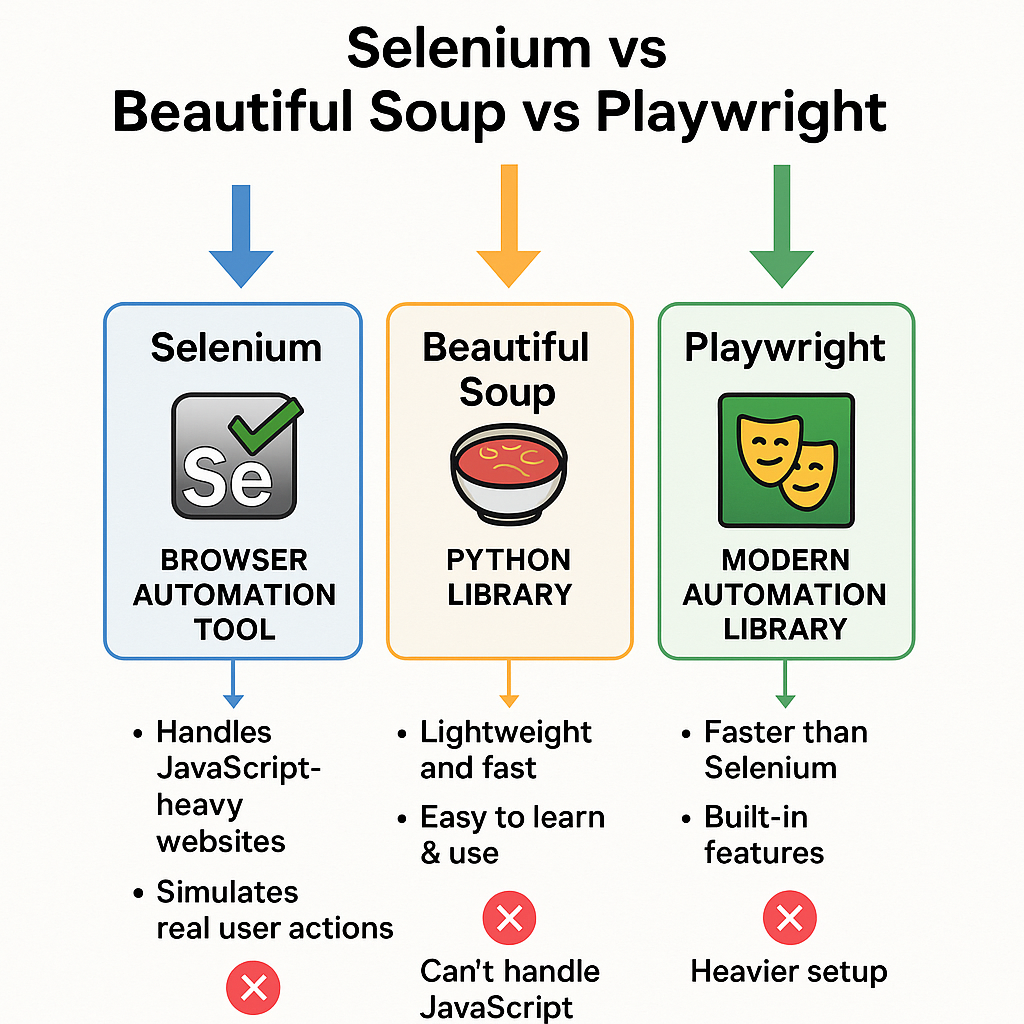
🥇 1. Selenium
🔹 What it is: A browser automation tool (controls Chrome, Firefox, Edge, etc.)
🔹 Use Case: Web scraping, testing web apps, automating clicks/forms/navigation
🔹 Strengths:
Can handle JavaScript-heavy websites (dynamic pages).
Simulates real user actions (click, scroll, input).
Works with multiple languages (Python, Java, C#, etc.).
🔹 Weaknesses:
Slower than BS/Playwright because it launches a real browser.
Can be easily detected by anti-bot systems.
✅ Best for: Web automation + scraping dynamic sites
🔹 What it is: A Python library for parsing and extracting data from HTML/XML.
🔹 Use Case: Data extraction from static pages or after you already fetched HTML with requests.
🔹 Strengths:
Very lightweight and fast.
Super easy to learn & use.
Works great for clean HTML parsing.
🔹 Weaknesses:
Cannot handle JavaScript-rendered content on its own.
Needs other tools (like requests, selenium, or playwright) to fetch dynamic content.
✅ Best for: Parsing clean static HTML
🔹 What it is: A modern automation library (by Microsoft) for web browsers.
🔹 Use Case: Web scraping, testing, and automation (like Selenium but newer and faster).
🔹 Strengths:
Handles JavaScript-heavy websites easily.
Much faster than Selenium (headless browser mode).
Built-in features: auto-waiting, multiple browser contexts, capturing screenshots, etc.
Can bypass some anti-bot protections better than Selenium.
🔹 Weaknesses:
Slightly newer, smaller community than Selenium.
Slightly heavier setup compared to BeautifulSoup.
✅ Best for: Fast & robust scraping of dynamic sites
| Feature | Selenium 🦾 | BeautifulSoup 🍜 | Playwright 🎭 |
|---|---|---|---|
| Language | Multi (Python, Java, etc.) | Python only | Multi (Python, JS, etc.) |
| Speed | ❌ Slow | ✅ Fast | ⚡ Very Fast |
| JS Handling | ✅ Yes | ❌ No | ✅ Yes |
| Ease of Use | Medium | ✅ Very Easy | Medium |
| Use Case | Automation + Scraping | Parsing static HTML | Modern automation + Scraping |
| Best For | Complex web apps | Simple sites | Dynamic sites, speed |
👉 Use BeautifulSoup if the site is static and you just need to parse HTML.
👉 Use Selenium if you need browser automation + scraping.
👉 Use Playwright if you need speed & dynamic scraping with modern sites.
 Continue With Google
Continue With Google  Programming
Programming

