Selenium is a powerful Python library (also available in Java, C#, etc.) used for:
🌐 Automating web browsers
🤖 Web scraping (especially dynamic websites with JavaScript)
🧪 Testing web applications
🔄 Performing repetitive tasks automatically
👉 Think of it as a robot that controls your browser 🖥️.
Works with JavaScript-rendered content (unlike BeautifulSoup).
Can click buttons, fill forms, scroll, login just like a human.
Supports multiple browsers (Chrome, Firefox, Edge, Safari).
Often used in end-to-end testing and web scraping.
pip install selenium
You’ll also need a WebDriver (e.g., chromedriver for Chrome).
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
# Launch Chrome
driver = webdriver.Chrome()
# Open Google
driver.get("https://www.google.com")
# Search for "Selenium Python"
search_box = driver.find_element("name", "q")
search_box.send_keys("Selenium Python")
search_box.send_keys(Keys.RETURN)
print(driver.title) # Print page title
driver.quit()
👉 Here:
webdriver.Chrome() → starts Chrome browser
find_element("name", "q") → locates Google search box
.send_keys("Selenium Python") → types text
.quit() → closes browser
Interface to control the browser.
Examples: webdriver.Chrome(), webdriver.Firefox()
Different ways to find elements:
driver.find_element("id", "username")
driver.find_element("name", "q")
driver.find_element("tag name", "h1")
driver.find_element("class name", "btn")
driver.find_element("css selector", "div.article h2")
driver.find_element("xpath", "//input[@type='text']")
👉 Use find_elements() for multiple matches.
element.click() # Click a button/link
element.send_keys("abc") # Type in a field
element.clear() # Clear input field
driver.get("https://example.com") # Go to URL
driver.back() # Back
driver.forward() # Forward
driver.refresh() # Refresh
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myElement"))
)
👉 Prevents errors if elements take time to load.
# Alert
alert = driver.switch_to.alert
alert.accept()
# iFrame
driver.switch_to.frame("frameName")
# New Window
driver.switch_to.window(driver.window_handles[1])
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("http://quotes.toscrape.com/js/")
quotes = driver.find_elements(By.CLASS_NAME, "text")
authors = driver.find_elements(By.CLASS_NAME, "author")
for q, a in zip(quotes, authors):
print(q.text, "-", a.text)
driver.quit()
👉 Unlike BeautifulSoup, this works even though the site loads quotes dynamically with JavaScript.
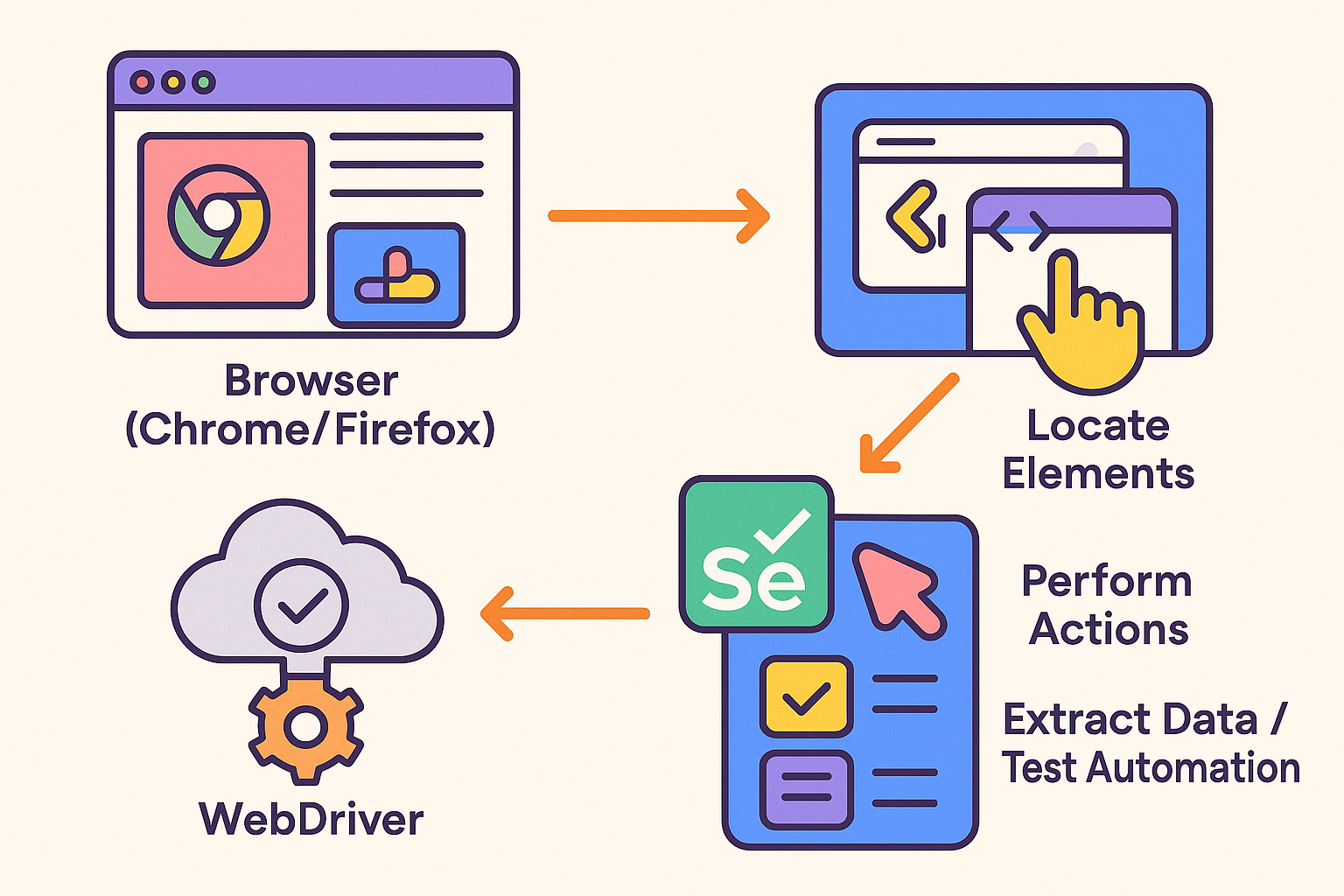
Browser (Chrome/Firefox) → WebDriver → Selenium Script → Locate Elements → Perform Actions → Extract Data / Test Automation
❌ Slower than BeautifulSoup (because it runs full browser).
❌ Requires browser drivers.
❌ High memory usage.
Use headless mode for speed:
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_argument("--headless")
driver = webdriver.Chrome(options=options)
Combine with BeautifulSoup for parsing once content is loaded.
Respect websites (robots.txt, delays).
✨ In short, Selenium = Browser Robot 🤖 that:
Opens websites 🌐
Clicks, types, scrolls like a human ⌨️
Extracts even JavaScript-powered data ⚡
 Continue With Google
Continue With Google  Programming
Programming

