It is more advanced and efficient than libraries like BeautifulSoup because it handles asynchronous requests, making it faster and scalable for large projects.
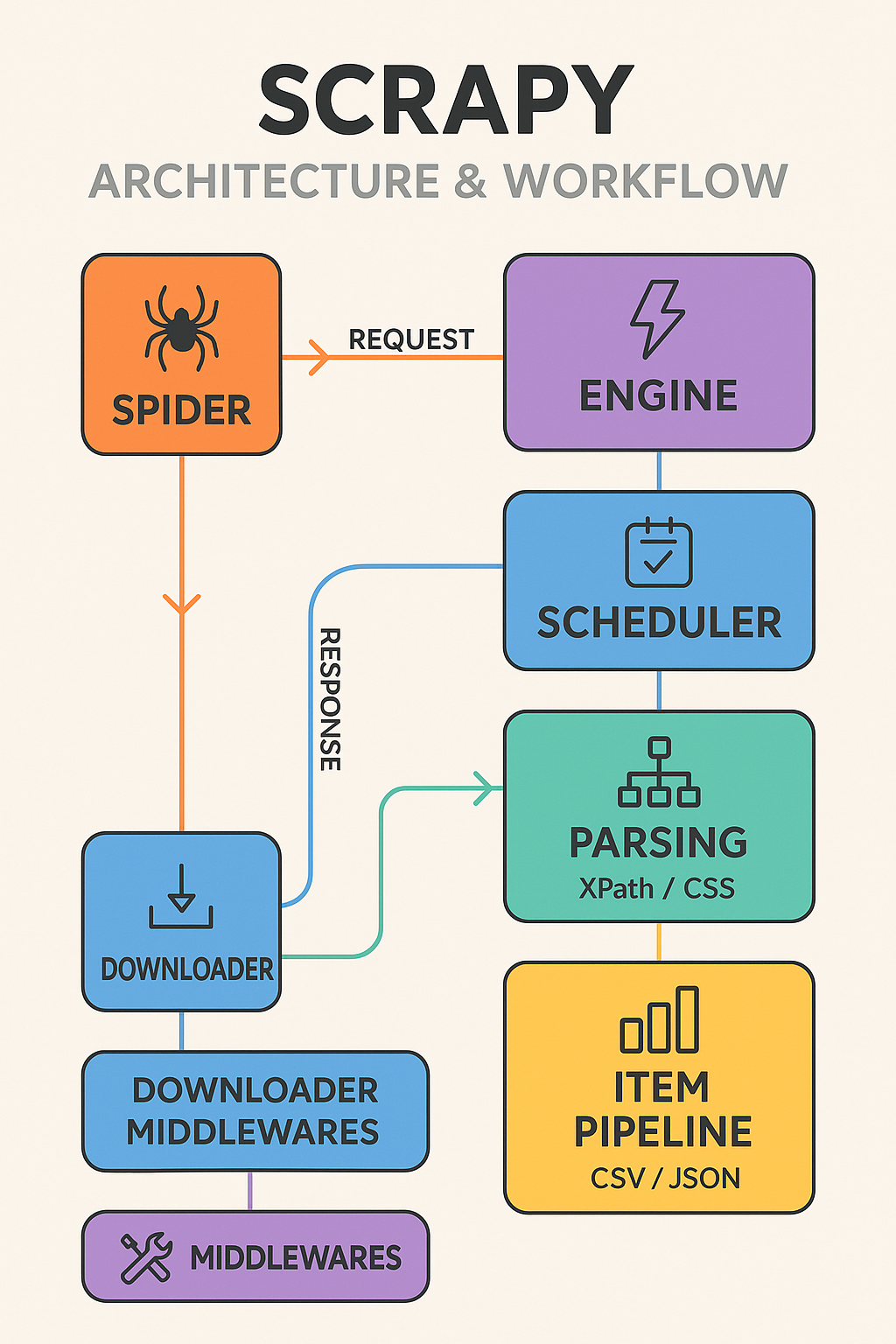
Scrapy works like a data pipeline, where data flows from request → response → parsing → item pipeline → storage.
Spider 🕷️
The "heart" of Scrapy.
Defines how a website will be crawled.
You write a Spider class that sends requests and parses responses.
Engine ⚡
The core component that controls the flow.
Coordinates between Spiders, Scheduler, Downloader, and Pipelines.
Scheduler 📋
Queues requests from Spiders and decides the next one to process.
Downloader 📥
Handles sending HTTP requests and getting responses from websites.
Downloader Middlewares 🔀
A layer between the engine and downloader.
Used for handling headers, proxies, retries, or user-agents.
Item Pipeline 📊
Where the extracted data goes after being parsed.
Can clean, validate, transform, or save data to CSV, JSON, database, etc.
Middlewares 🛠️
Custom processing at request/response level.
E.g., handling CAPTCHAs, rotating proxies, or cookies.
Spider sends an initial Request to a website.
Downloader fetches the webpage.
Response goes back to the Spider.
Spider parses HTML/XML using Selectors (XPath / CSS).
Extracted data becomes an Item.
Item is passed through the Pipeline for cleaning/saving.
New links found on the page may generate new Requests (crawl continues).
✅ Asynchronous & Fast – Uses Twisted (event-driven networking engine).
✅ Selectors – Supports XPath & CSS selectors for parsing.
✅ Built-in Export – Save data to JSON, CSV, XML easily.
✅ Middleware Support – Rotate user agents, handle proxies, retries.
✅ Auto Throttle – Adjusts crawling speed to avoid blocking.
✅ Robust Crawling – Can handle millions of pages.
✅ Extensible – Easy to plug in pipelines, middlewares, or custom logic.
| Tool | Type | Best For |
|---|---|---|
| BeautifulSoup | Parsing Library | Small projects, single page parsing |
| Selenium | Browser Automation | JavaScript-heavy sites, dynamic pages |
| Scrapy | Full Framework | Large-scale crawling & structured data extraction |
pip install scrapy
scrapy startproject quotes_scraper
cd quotes_scraper
spiders/quotes_spider.py):import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = ["http://quotes.toscrape.com/"]
def parse(self, response):
for quote in response.css("div.quote"):
yield {
"text": quote.css("span.text::text").get(),
"author": quote.css("small.author::text").get(),
"tags": quote.css("div.tags a.tag::text").getall(),
}
# follow next page
next_page = response.css("li.next a::attr(href)").get()
if next_page:
yield response.follow(next_page, self.parse)
scrapy crawl quotes -o quotes.json
This will crawl all quotes and save them in quotes.json.
🔎 E-commerce (price monitoring, product data collection)
📰 News Aggregation
📚 Research Data Extraction
🌍 Crawling websites for SEO analysis
💼 Business Intelligence (competitive analysis)
💡 In short:
Scrapy = Fast, Scalable, and Professional Web Scraping Framework
Perfect when you want to crawl multiple pages/sites and store structured data efficiently.
 Continue With Google
Continue With Google  Programming
Programming

