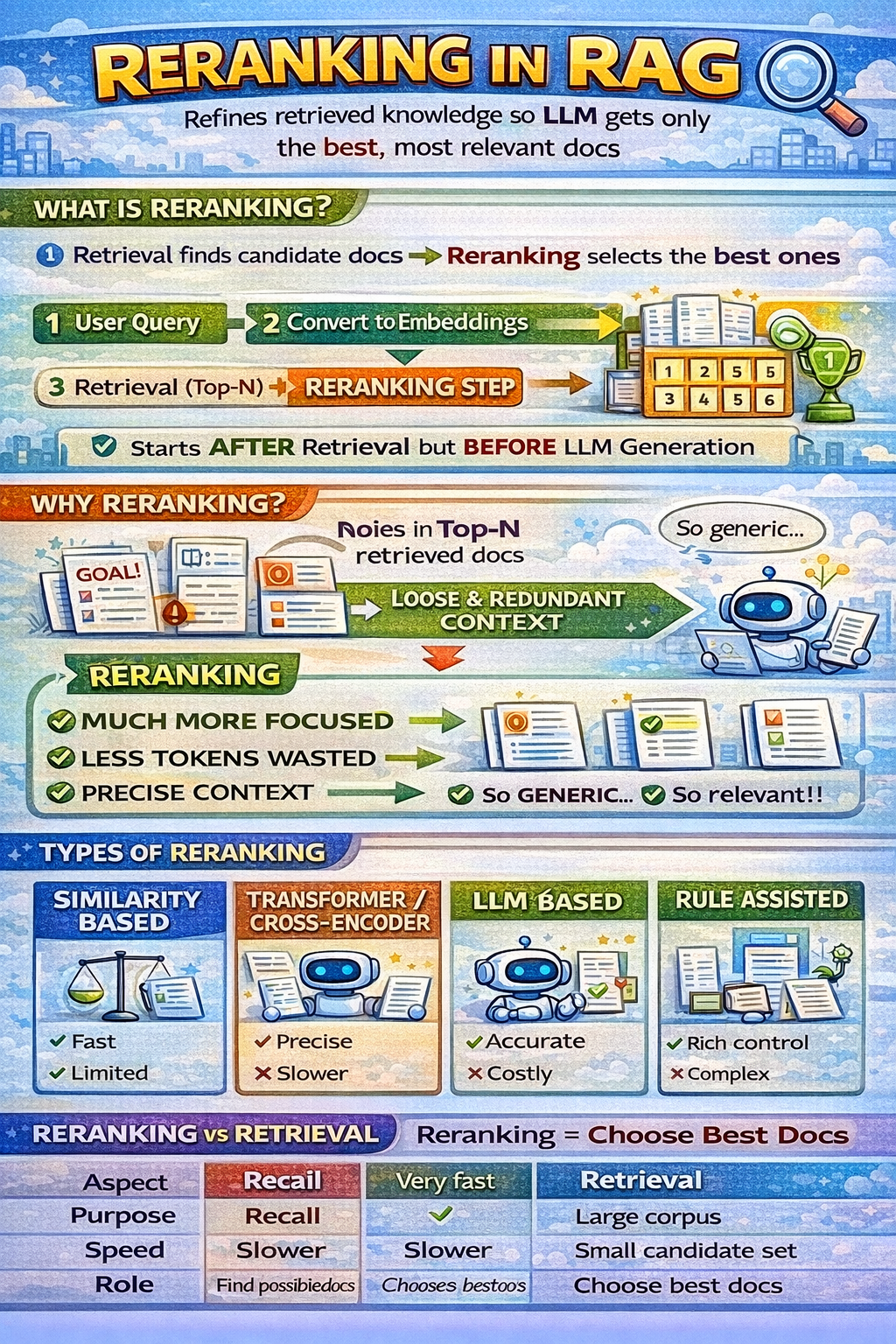
Reranking is a post-retrieval optimization step in a Retrieval-Augmented Generation (RAG) pipeline.
It reorders (and often filters) the initially retrieved documents so that the most contextually relevant information is finally sent to the LLM.
In simple terms:
Retrieval finds candidates → Reranking chooses the best ones
A standard RAG flow looks like this:
User query
Query embedding
Vector / hybrid retrieval (top-N documents)
Reranking (top-K refined documents) ← ⭐
Prompt construction
LLM generation
Reranking happens after retrieval but before generation.
Vector databases retrieve documents based on embedding similarity, which is:
Approximate
Geometry-based
Sometimes semantically loose
This can lead to:
Slightly off-topic chunks
Redundant information
Missing critical but subtle context
Reranking:
Applies deeper semantic understanding
Considers query-document interaction
Improves precision at top-K
In RAG, top-3 quality matters more than top-20 quantity.
Given:
A user query Q
A retrieved candidate set D = {d₁, d₂, … dₙ}
Reranking:
Scores each (Q, dᵢ) pair using a stronger model
Reorders documents by this score
Keeps only the best K documents
The LLM sees only high-signal context.
Uses cosine similarity again
Applies normalization or weighting
Fast, but limited improvement
Used when:
Low latency is critical
Dataset is already clean
How it works:
Query and document are passed together into a transformer
Model evaluates relevance jointly
Key idea:
The model reads query + document together, not separately
Why it’s powerful:
Understands nuance
Captures intent
Handles negation and context
Trade-off:
Slower than vector similarity
Used on small candidate sets (top-20 → top-5)
How it works:
LLM evaluates and scores retrieved chunks
Sometimes explains its choice
Strengths:
Highest semantic accuracy
Works well for complex queries
Weaknesses:
Expensive
Latency
Needs guardrails
Used in:
High-value domains (legal, medical)
Agentic RAG systems
Combines:
Semantic score
Metadata rules (recency, source, authority)
Example:
Prefer newer policy documents
Penalize low-trust sources
Used in:
Enterprise RAG
Compliance-driven systems
| Aspect | Retrieval | Reranking | |||
|---|---|---|---|---|---|
| Purpose | Recall | Precision | |||
| Speed | Very fast | Slower | |||
| Model | Embeddings | Deep models / LLMs | |||
| Scope | Large corpus | Small candidate set | |||
| Role | Find possible docs | Choose best docs |
Retrieval answers “what could be relevant?”
Reranking answers “what is most relevant?”
MMR reduces redundancy among documents
Reranking improves relevance ordering
They are often used together:
Retrieve top-N
Apply MMR (diversity)
Apply reranking (precision)
Without reranking:
Hallucinations increase
Answers feel generic
Context misses intent
With reranking:
Answers are focused
Fewer tokens wasted
Higher factual grounding
Many RAG failures are retrieval successes but reranking failures.
Most production RAG systems use:
Hybrid retrieval (keyword + vector)
MMR for diversity
Cross-encoder reranking for precision
Token-budget-aware chunk selection
Reranking is treated as a quality gate before the LLM.
Pros:
Dramatically improves answer quality
Reduces hallucination
Better use of context window
Cons:
Adds latency
Adds cost
Needs careful tuning (top-N → top-K)
Reranking is the intelligence layer in RAG that refines retrieved knowledge so the LLM receives only the most relevant, high-signal context.
 Continue With Google
Continue With Google  Data Science
Data Science
 AI: Artificial intelligence
AI: Artificial intelligence

