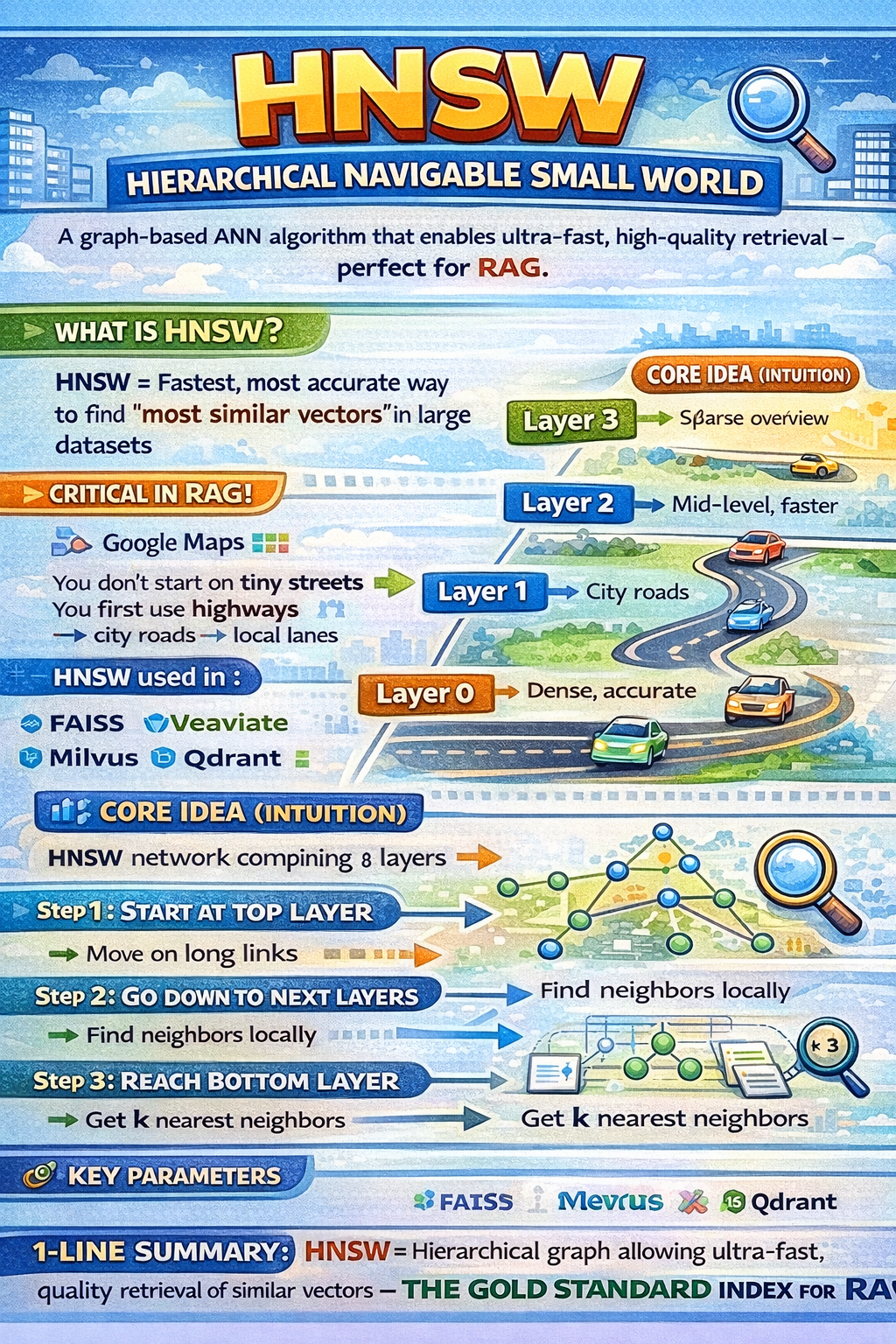
HNSW (Hierarchical Navigable Small World) is a graph-based Approximate Nearest Neighbor (ANN) search algorithm.
In simple words:
HNSW is the fastest and most accurate way to find “most similar vectors” in large datasets — which makes it the backbone of RAG retrieval.
In Retrieval-Augmented Generation (RAG), the pipeline is:
User Query → Embedding → Vector Search → Context → LLM Answer
👉 The Vector Search step must be:
⚡ Fast (milliseconds)
🎯 Accurate (semantic relevance)
📈 Scalable (millions of vectors)
✅ HNSW solves all three
That’s why it is used internally by:
FAISS
Milvus
Weaviate
Qdrant
Pinecone (conceptually)
Think of Google Maps 🗺️:
You don’t start driving on small streets
You first use highways
Then city roads
Then local lanes
HNSW works exactly like this.
Top layer → very few nodes (high-level overview)
Bottom layer → all vectors (full detail)
Layer 3 (Very sparse, fast jumps)
Layer 2
Layer 1
Layer 0 (All vectors, accurate)
Pick an entry point
Move greedily to closest node
Use best candidate from above
Search locally again
Fine-grained search
Get top-k nearest neighbors
✅ Result: Fast + accurate retrieval
In small-world graphs:
Any node can be reached in very few hops
Similar to social networks (6 degrees of separation)
HNSW builds such a graph over embeddings.
M – Max Connections per NodeControls graph density
| M Value | Effect |
|---|---|
| Low | Faster, less accurate |
| High | More accurate, more memory |
👉 Typical: 16 – 64
ef_constructionQuality during index building
| Value | Meaning |
|---|---|
| Low | Faster build |
| High | Better graph |
👉 Typical: 100 – 400
ef_searchSearch accuracy vs speed
| Value | Effect |
|---|---|
| Low | Fast, approximate |
| High | Slower, accurate |
👉 In RAG: ef_search > k is recommended
❌ Slow retrieval
❌ Poor scaling
❌ LLM waits
✅ Millisecond search
✅ Millions of docs
✅ Real-time RAG chat
📌 Retrieval quality = Answer quality
| Method | Speed | Accuracy | Scale |
|---|---|---|---|
| Flat (Brute Force) | ❌ | ✅ | ❌ |
| IVF | ⚡ | ⚠️ | ✅ |
| PQ | ⚡⚡ | ❌ | ✅ |
| HNSW | ⚡⚡⚡ | ✅ | ✅✅ |
👉 HNSW = Best default choice
Instant context retrieval
PDFs, policies, manuals
Accurate & diverse evidence
Multiple tool calls → fast retrieval
Higher memory usage
Index build is slower
Not ideal for very frequent deletes
📌 But for read-heavy RAG systems, it’s perfect.
HNSW is a hierarchical graph-based ANN algorithm that enables ultra-fast, high-quality semantic retrieval — making it the gold standard index for RAG systems.
“In RAG, embeddings give meaning, but HNSW gives speed and scalability — without it, real-time AI is impossible.”
 Continue With Google
Continue With Google  Data Science
Data Science
 AI: Artificial intelligence
AI: Artificial intelligence

