🌍 What is Goose?
Goose is a content extraction library originally written in Java and later ported to Python.
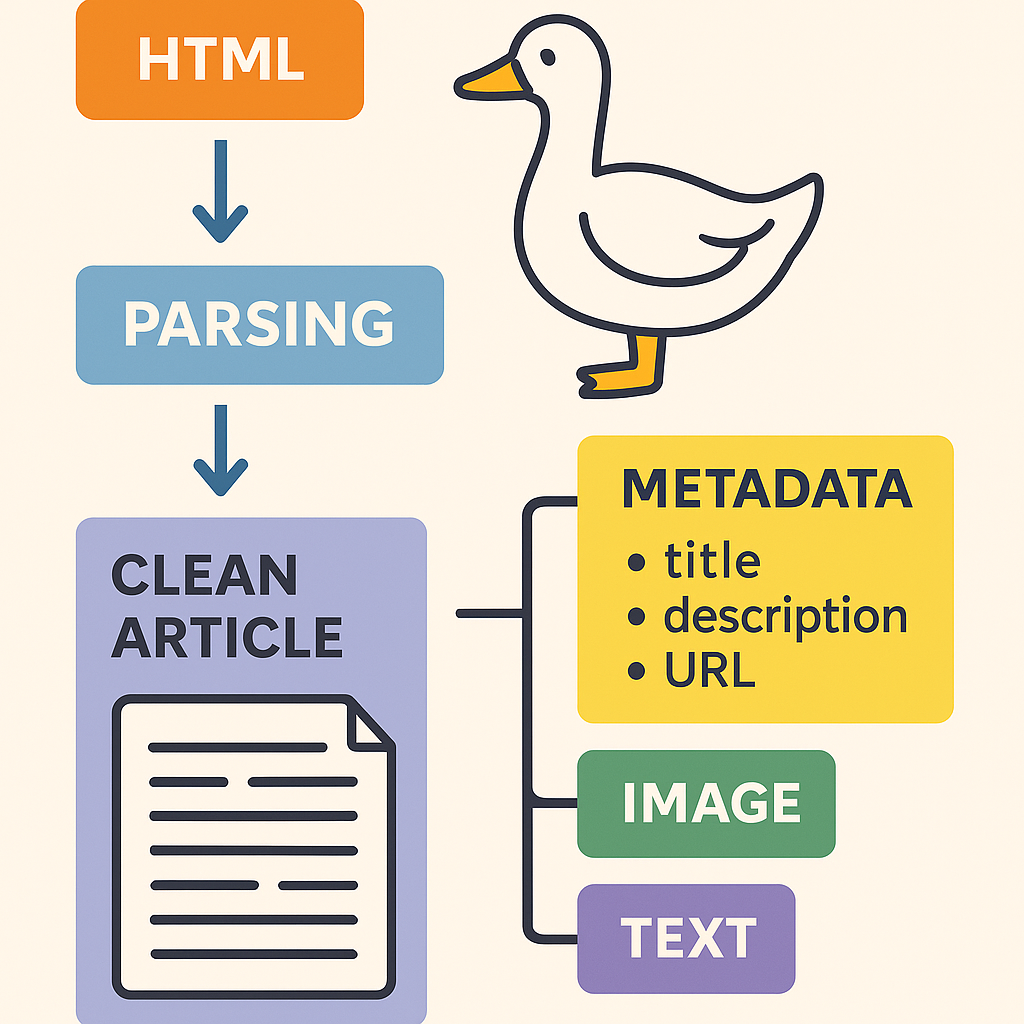
Its main goal is to take a messy HTML page (like a news site, blog, or magazine article) and extract the main clean text content, along with useful metadata.
Think of Goose as a "content miner" ⛏️ for web pages:
Removes ads, navigation menus, and clutter.
Extracts the title, body text, images, meta info, and videos.
Outputs a clean, structured format for further use in apps, NLP, or data pipelines.
When you pass a URL or raw HTML, Goose uses a series of parsing and cleaning techniques:
Download / Load HTML
Goose fetches the page (if URL given) or takes raw HTML input.
HTML Parsing (via lxml / BeautifulSoup-like parsing)
It breaks the HTML into a structured DOM tree.
Content Extraction Logic
Goose applies heuristics to:
Identify the largest continuous text block (usually the main article).
Score content blocks based on density of text vs. links/images.
Filter out sidebars, menus, ads, comments, etc.
Metadata Extraction 🧾
Goose extracts:
title → from <title> or <meta property="og:title">
meta description
canonical URL
tags / keywords
Media Extraction 🖼️
Goose can also pull:
Top image (og:image, or the most relevant one in the article)
Embedded videos
Cleanup & Output
The extracted data is returned as an Article object in Python.
from goose3 import Goose
# Initialize Goose
g = Goose()
# Extract from a URL
article = g.extract(url="https://example.com/some-news-article")
print("Title:", article.title)
print("Meta Description:", article.meta_description)
print("Cleaned Text:\n", article.cleaned_text[:500]) # first 500 chars
print("Top Image:", article.top_image.src if article.top_image else None)
✅ Output is super clean compared to raw HTML scraping.
Goose (Python port) is available as goose3 (active fork):
pip install goose3
Article text extraction → main body only
Title detection
Meta info extraction → description, keywords, canonical URL
Image extraction → finds the most relevant image
Language detection 🌐 (multi-language support)
HTML noise removal
📰 News Aggregators → Extract clean text for summaries.
📚 Content Mining → Feed into NLP pipelines (summarization, sentiment analysis).
🔍 SEO Tools → Extract metadata and content.
📖 Content Archiving → Save clean versions of articles.
🤖 Chatbots & AI → Provide structured knowledge from messy pages.
Struggles with heavily JavaScript-rendered pages (like React/Angular apps).
Sometimes misidentifies content if page structure is unusual.
Development is not as active as some modern alternatives like:
Newspaper3k 📰 (better maintained for Python)
Readability.js (Node.js based)
| Tool | Language | Best For | Pros | Cons |
|---|---|---|---|---|
| Goose3 | Python | News & blogs | Simple, accurate, image extraction | Not great with JS-heavy sites |
| Newspaper3k | Python | Articles & NLP | Active dev, multilingual, NLP ready | Slower sometimes |
| Readability.js | JS | Browser/article parsing | Built by Mozilla, strong JS support | Not native in Python |
✨ In short:
Goose is a fast, lightweight, and effective tool for article parsing and metadata extraction in Python.
If you want clean text and metadata from blogs/news sites with minimal setup, Goose is still a reliable choice. 🪿📄
 Continue With Google
Continue With Google  Programming
Programming

