👉 Short answer:
No, a Document DB is not a Vector DB by design.
But yes, you can extend or integrate a Document DB to act like one. Let me explain:
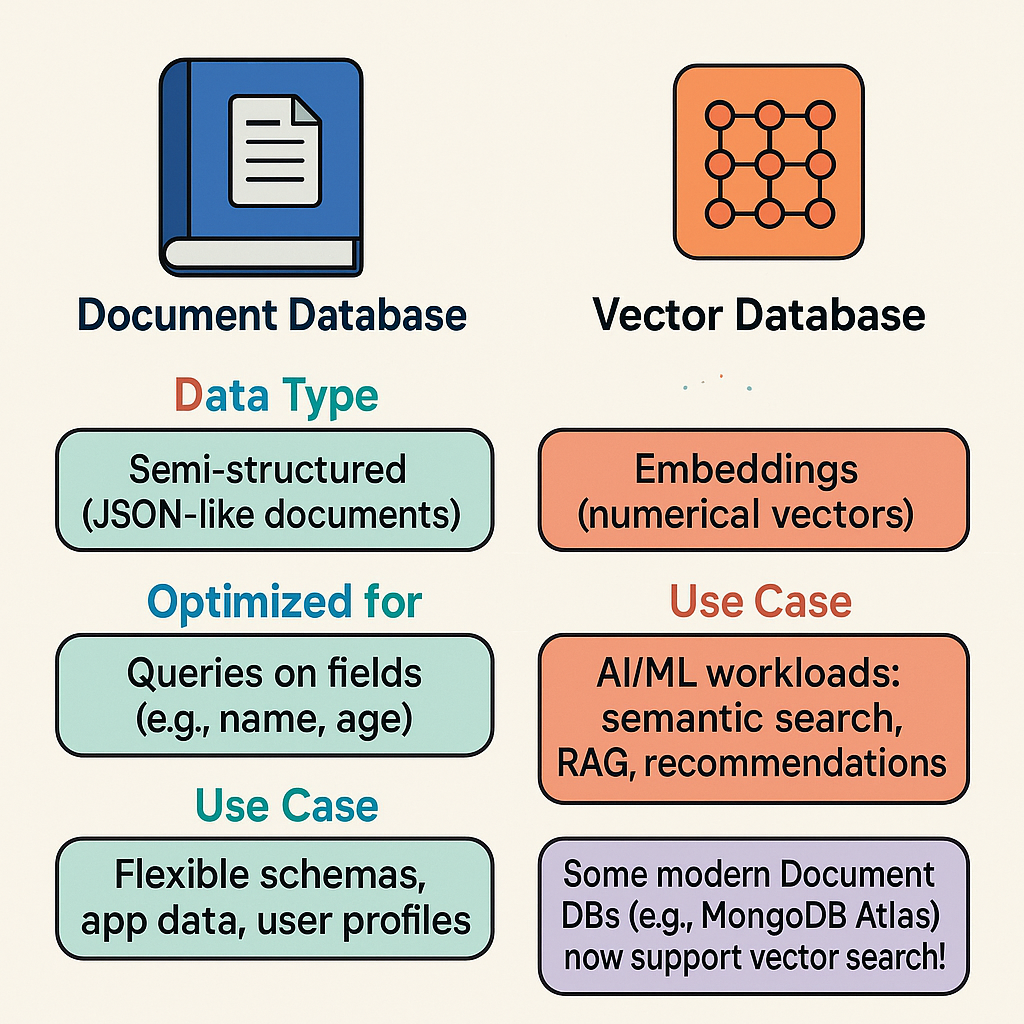
Stores semi-structured data (JSON-like documents).
Great for flexible schemas, nested objects, user profiles, and app data.
Optimized for queries on fields (e.g., name, age, category).
Stores embeddings (numerical vector representations).
Optimized for similarity search using algorithms like cosine similarity, dot product, Euclidean distance.
Used for AI/ML workloads: semantic search, RAG (Retrieval-Augmented Generation), recommendations, etc.
Document DBs don’t natively support vector indexing & similarity search, but you can still store vectors inside documents.
{
"id": "doc_1",
"title": "AI in Healthcare",
"content": "AI improves diagnosis accuracy",
"embedding": [0.123, 0.456, 0.789, ...] // vector representation
}
✅ You can store vectors inside the document.
❌ But searching for "nearest vectors" (like semantic search) is slow without special support.
Some modern Document DBs are adding vector search capabilities:
MongoDB Atlas (latest versions) → supports Vector Search Indexes.
Amazon DocumentDB → experimenting with vector search integration.
Elasticsearch (though not purely document DB) → has strong vector search support.
If your app is document-heavy with occasional vector search needs → Use MongoDB with vector search extension.
If your app is AI-driven (chatbots, semantic search, recommendations) → Use a dedicated Vector DB like Pinecone or Weaviate.
You can also hybrid → store documents in MongoDB & embeddings in Pinecone (common in RAG setups).
🌟 In summary:
A Document DB is not a Vector DB by nature.
You can store embeddings in it, but performance won’t match a true vector DB.
Some Document DBs (like MongoDB Atlas) now support vector search, bridging the gap.
 Continue With Google
Continue With Google  Programming
Programming

