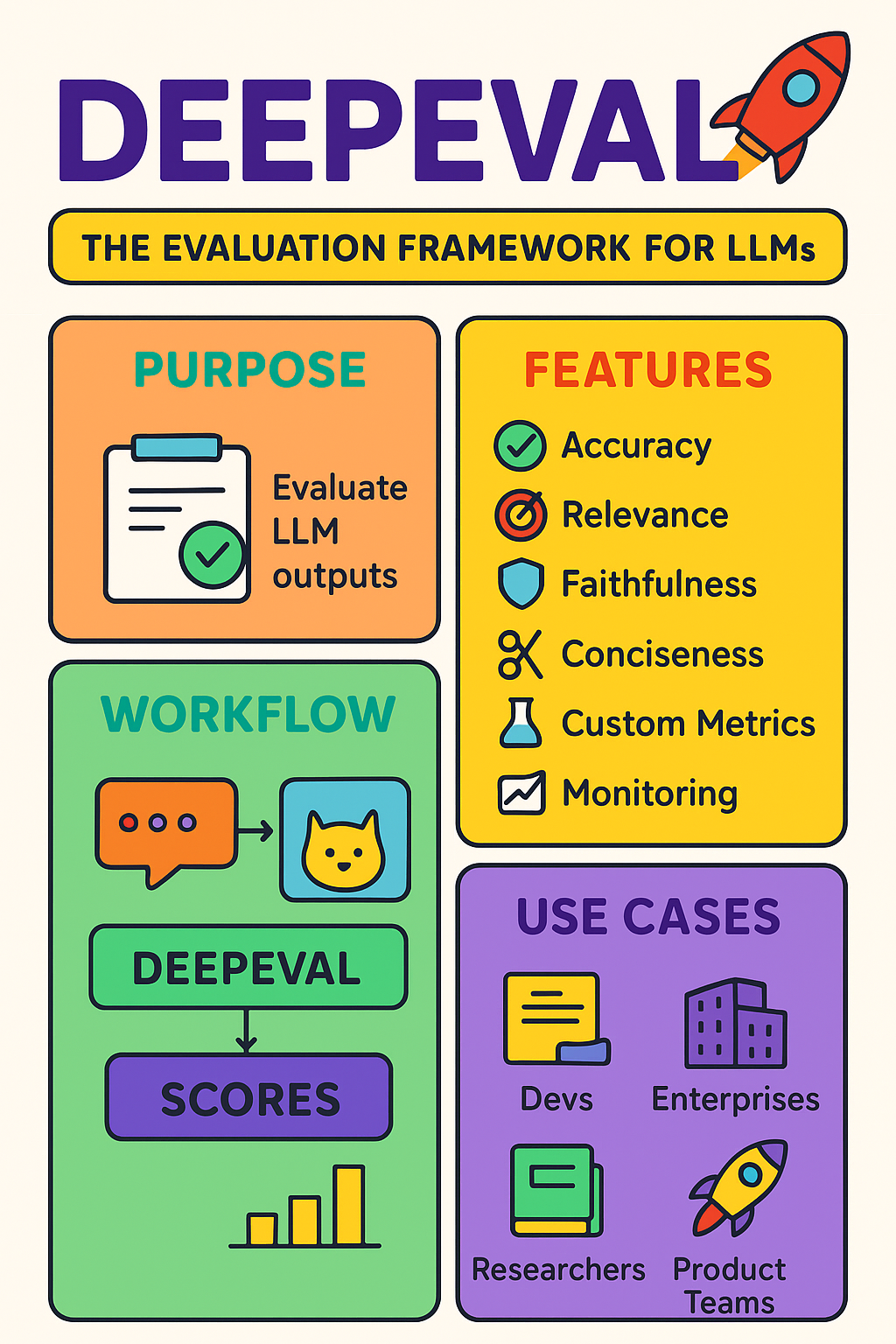
DEEPEVAL is an open-source evaluation framework designed to test, benchmark, and monitor Large Language Models (LLMs).
It helps developers, researchers, and businesses understand how well an LLM is performing—not just in terms of accuracy, but also reliability, safety, and overall quality.
✅ Evaluate LLM outputs systematically
🎯 Provide standardized metrics (so results are comparable)
⚡ Support real-time monitoring for production use
🌟 a. Standard Metrics
Accuracy → How correct is the output?
Relevance → Does it match the query context?
Faithfulness → Is it hallucination-free?
Conciseness → Is it precise without fluff?
🌟 b. Custom Metrics
Build your own evaluation rules (e.g., domain-specific compliance like finance or healthcare).
🌟 c. Multi-Dataset Testing
Compare performance across different datasets for robustness.
🌟 d. Benchmarks
Compare your model against popular baselines (OpenAI, Anthropic, etc.).
🌟 e. Continuous Monitoring
Detect model drift and performance degradation in production.
Think of it like a school exam system for LLMs 🏫
1️⃣ Test Paper (Prompt Dataset)
Provide prompts or scenarios.
2️⃣ Student (LLM)
The model generates answers.
3️⃣ Examiner (DEEPEVAL)
Applies evaluation metrics automatically.
4️⃣ Report Card
Scores on accuracy, relevance, safety, etc.
5️⃣ Comparison
Benchmark results with other models.
✨ For Developers → Debug LLM outputs before launch.
✨ For Enterprises → Ensure compliance (no hallucinations in finance/health).
✨ For Researchers → Benchmark across datasets.
✨ For Product Teams → Track quality in real-time.
LLMs are powerful but unpredictable. Without proper evaluation, they might:
⚠️ Give hallucinated answers
⚠️ Show bias or toxicity
⚠️ Perform inconsistently across domains
👉 DEEPEVAL ensures trust, safety, and quality in LLM-powered products.
┌─────────────────────────────┐
│ DEEPEVAL 🚀 │
└─────────────────────────────┘
│
▼
🧩 PURPOSE → Evaluate LLM outputs
│
▼
⚙️ FEATURES
- Accuracy ✔️
- Relevance 🎯
- Faithfulness 🛡️
- Conciseness ✂️
- Custom Metrics 🧪
- Monitoring 📈
│
▼
🛠️ WORKFLOW
Prompts → LLM → DEEPEVAL → Scores
│
▼
🎭 USE CASES
- Devs 🧑💻
- Enterprises 🏢
- Researchers 📚
- Product Teams 🚀
✨ In short: DEEPEVAL = Report card + Exam system + Monitoring tool for LLMs 📝🤖
 Continue With Google
Continue With Google  Programming
Programming

