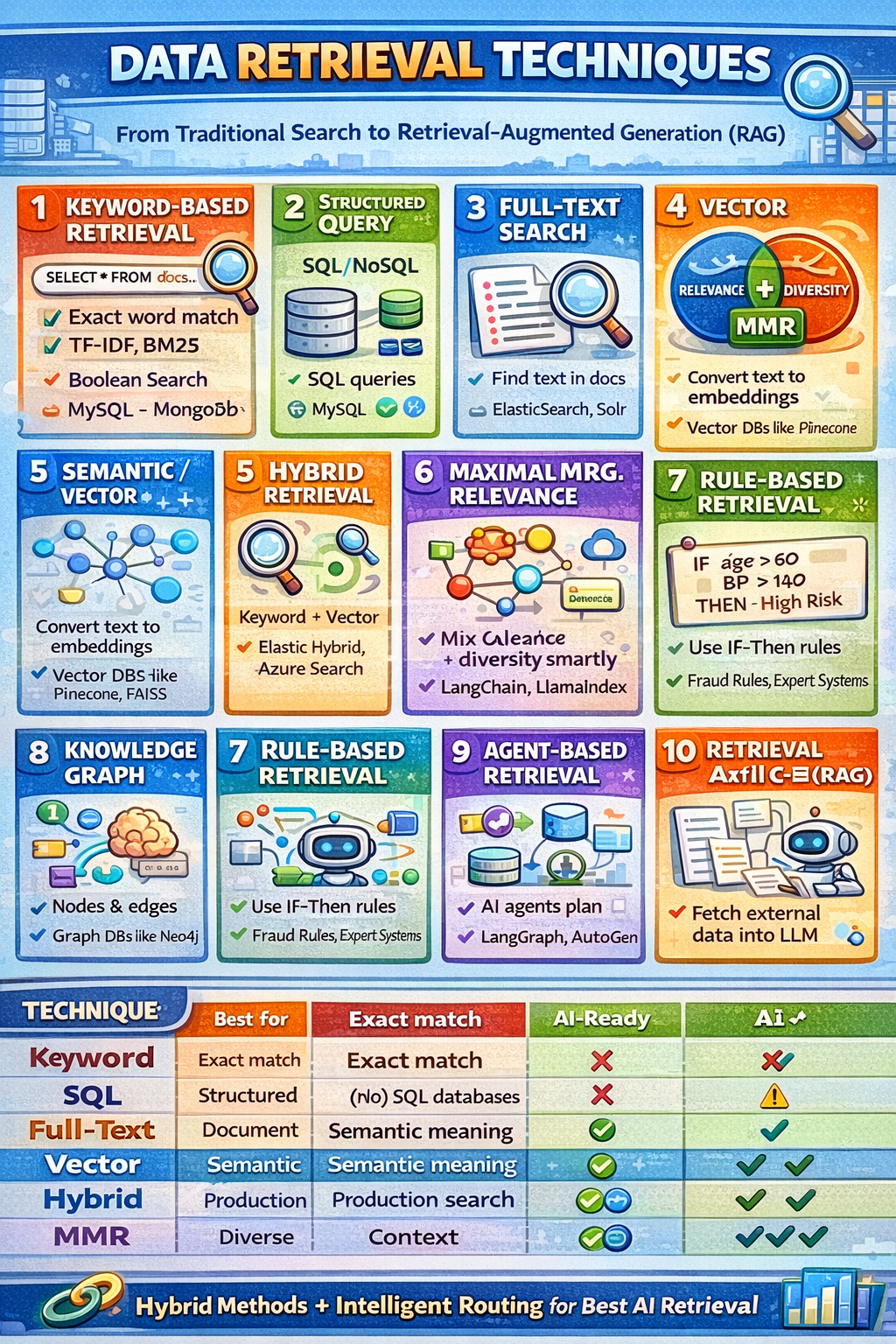
Data Retrieval is the process of finding, selecting, and returning relevant data from a storage system (databases, files, indexes, vector stores, APIs) based on a user query or task.
The technique you choose depends on:
Data type (structured / unstructured)
Query type (exact / semantic)
Scale (MB → TB)
Latency requirements
AI vs non-AI usage
Matches exact words or tokens
Uses inverted indexes
Boolean Search
TF-IDF
BM25
Query: “diabetes treatment”
Retrieved only documents containing those exact words
Fast
Deterministic
Easy to debug
No semantic understanding
Fails with synonyms
SQL LIKE
ElasticSearch (lexical)
Traditional search engines
Queries predefined schemas
Uses indexes, joins, filters
SELECT * FROM patients WHERE age > 50 AND disease='CKD';
Highly accurate
Transaction-safe
Optimized with indexes
Schema rigid
Not suitable for text meaning
MySQL, PostgreSQL
MongoDB
DynamoDB
Tokenizes text
Ranks relevance using scoring
Search inside PDFs, blogs, documents
Faster than raw keyword
Ranking supported
Still lexical
No deep meaning
ElasticSearch
PostgreSQL Full-Text Search
Solr
Converts text into vectors
Measures semantic similarity
Query: “How to control sugar?”
Retrieves: “Diabetes management guidelines”
Understands meaning
Handles synonyms
Best for AI systems
Approximate results
Needs embedding models
FAISS
Pinecone
ChromaDB
Weaviate
Combines lexical precision + semantic recall
Keyword ensures domain match
Vector ensures meaning match
Best of both worlds
Industry standard
More complex
Needs tuning
ElasticSearch Hybrid
Azure AI Search
LangChain hybrid retrievers
Selects documents that are:
Relevant to query
Diverse from each other
Avoids returning same paragraph reworded 5 times
Reduces redundancy
Improves RAG output
Slightly slower
LangChain
LlamaIndex
RAG pipelines
Data stored as nodes and relationships
Query via graph traversal
Patient → hasDisease → Diabetes → treatedBy → Metformin
Explainable
Logical reasoning
Complex to build
Schema heavy
Neo4j
Amazon Neptune
Semantic Web (RDF/SPARQL)
Uses predefined rules & filters
IF age > 60 AND BP > 140 → High Risk
Deterministic
Auditable
Not scalable
Hard to maintain
Expert systems
Compliance engines
Agent decides:
Where to search
How to retrieve
When to stop
Agent queries:
Vector DB
SQL
Web API
→ merges results
Autonomous
Context aware
Costly
Needs guardrails
Agentic RAG
AutoGen
CrewAI
LangGraph
Retrieve external knowledge
Inject into LLM prompt
Generate grounded answer
Reduces hallucination
Uses private data
Retrieval quality matters a lot
Enterprise chatbots
Medical & legal AI
| Technique | Best For | AI-Ready |
|---|---|---|
| Keyword | Exact match | ❌ |
| SQL | Structured data | ❌ |
| Full-Text | Document search | ⚠️ |
| Vector | Semantic meaning | ✅ |
| Hybrid | Production search | ✅✅ |
| MMR | Diverse context | ✅ |
| Knowledge Graph | Reasoning | ✅ |
| Agentic | Autonomous AI | ✅✅✅ |
Modern AI systems never rely on a single retrieval technique.
They combine Hybrid + MMR + Agentic routing for best results.
Data retrieval has evolved from exact matching to meaning-aware, agent-driven intelligence — and retrieval quality defines AI quality.
 Continue With Google
Continue With Google  Data Science
Data Science
 AI: Artificial intelligence
AI: Artificial intelligence

