Camelot is a Python library that makes it easy to extract tables from PDF files and convert them into structured formats like CSV, Excel, JSON, or Pandas DataFrames.
Unlike OCR tools (like Tesseract), Camelot is designed specifically for tabular data in PDFs, so it can intelligently detect and parse rows/columns.
📊 Extracts tables directly into Pandas DataFrames.
📂 Exports tables into CSV, Excel, JSON, HTML formats.
🖼️ Supports two parsing methods:
Lattice → works best with PDFs that have lines/borders around cells.
Stream → works best with PDFs where tables are defined by spaces/whitespaces, without explicit borders.
📑 Can handle multi-page PDFs and extract multiple tables from each page.
⚡ Lightweight and easy to use (pure Python, no heavy dependencies except ghostscript for image-based parsing).
You can install Camelot with pip:
pip install "camelot-py[cv]"
cv installs OpenCV, which is required for the lattice mode.
You may also need Ghostscript installed separately (for working with certain PDFs).
Detects tables using lines and borders.
Works best when the table has clear row/column separators.
Example:
| Name | Age | Country |
|--------|-----|---------|
| Abhi | 30 | India |
Extracts very accurate results if the table is well-drawn.
Detects tables using whitespace alignment.
Useful when tables don’t have borders, just spacing.
Example:
Name Age Country
Abhi 30 India
Rahul 28 USA
More error-prone than lattice but powerful when borders are missing.
import camelot
# Reading tables from a PDF
tables = camelot.read_pdf("example.pdf", pages="1", flavor="lattice")
print("Total tables found:", tables.n)
print(tables[0].df) # Print first table as DataFrame
# Export first table to CSV
tables[0].to_csv("output.csv")
# Export all tables to Excel
tables.export("tables.xlsx", f="excel")
tables = camelot.read_pdf("example.pdf", pages="1", flavor="stream")
for i, table in enumerate(tables):
print(f"Table {i+1}")
print(table.df)
Finance/Banking → Extracting tabular data from financial reports, invoices, statements.
Healthcare → Extracting tables from medical trial results in research PDFs.
Data Science → Preprocessing government reports, survey results, census PDFs.
Business Intelligence → Parsing competitor product lists, catalogs, or regulatory documents.
Easy integration with Pandas for data analysis.
Handles both bordered and borderless tables.
Exports in multiple structured formats.
Open-source and actively maintained.
❌ Doesn’t work well with scanned PDFs (use OCR tools like Tesseract + Camelot for those).
❌ Complex tables (merged cells, nested headers) may cause errors.
❌ Requires manual tweaking (flavor, edge_tol, row_tol, etc.) for best accuracy.
❌ Ghostscript/OpenCV dependencies can be tricky to install on some systems.
Tabula-py → Another popular Python wrapper for Tabula (Java-based).
pdfplumber → More versatile (not only tables, but text extraction too).
PyMuPDF (fitz) → Lower-level PDF parsing, can be combined with table detection logic.
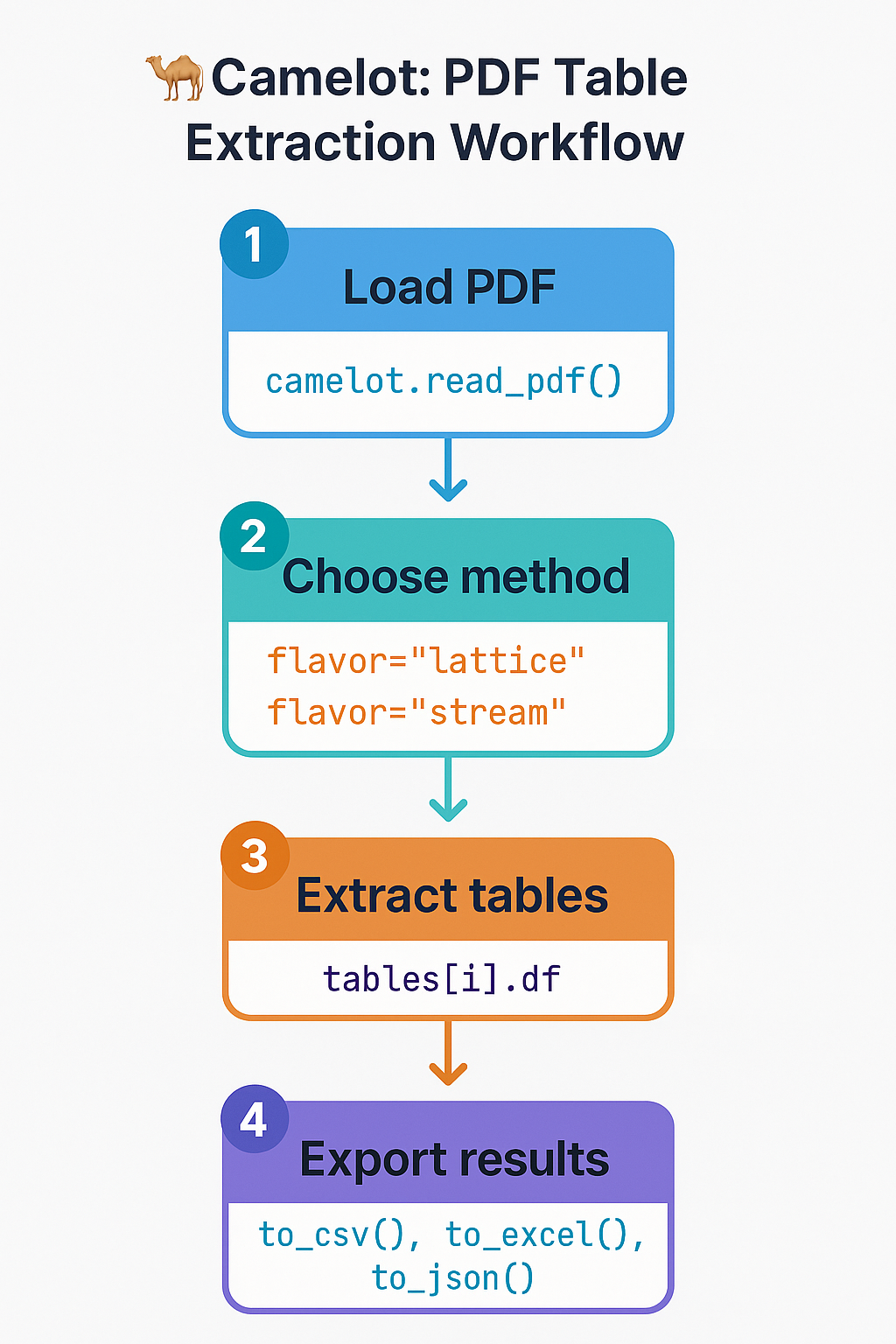
1️⃣ Load PDF → camelot.read_pdf()
2️⃣ Choose method → flavor="lattice" OR flavor="stream"
3️⃣ Extract tables → tables[i].df
4️⃣ Export results → to_csv(), to_excel(), to_json()
 Continue With Google
Continue With Google  Programming
Programming

