BeautifulSoup is a Python library that is used to parse HTML and XML documents.
Think of it like a "Google Maps for websites" – it helps you navigate through a webpage’s structure (tags, attributes, text) and extract the data you need.
👉 Officially, it is part of the web scraping toolkit.
🌐 Extract data from websites (news, e-commerce, weather, etc.)
📝 Convert messy HTML into structured data
🚀 Works well with requests or urllib to fetch webpage content
💡 Provides simple methods like .find(), .find_all(), .select()
pip install beautifulsoup4
(Optionally, you may need a parser: lxml or html5lib)
1️⃣ Import & Fetch Content
import requests
from bs4 import BeautifulSoup
url = "https://example.com"
response = requests.get(url)
2️⃣ Create Soup Object
soup = BeautifulSoup(response.text, "html.parser")
3️⃣ Navigate & Extract Data
# Title of page
print(soup.title.string)
# First <h1> tag
print(soup.h1.text)
# All links
for link in soup.find_all('a'):
print(link['href'])
soup.title → <title>Example Domain</title>
soup.h1 → First <h1> tag
soup.p → First <p> tag
soup.find('h1') → Finds first h1
soup.find_all('p') → Finds all p tags
soup.find('a', {'class': 'link'}) → Find tag with specific attribute
soup.select("div.article h2")
👉 Selects all <h2> inside <div class="article">
link = soup.find('a')
print(link['href']) # URL inside <a>
print(soup.get_text()) # Full plain text
📌 Scraping Quotes from a Website
import requests
from bs4 import BeautifulSoup
url = "http://quotes.toscrape.com/"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
for quote in soup.find_all('span', class_="text"):
print(quote.text)
👉 Output:
“The world as we have created it is a process of our thinking.”
“It is our choices, Harry, that show what we truly are.”
...
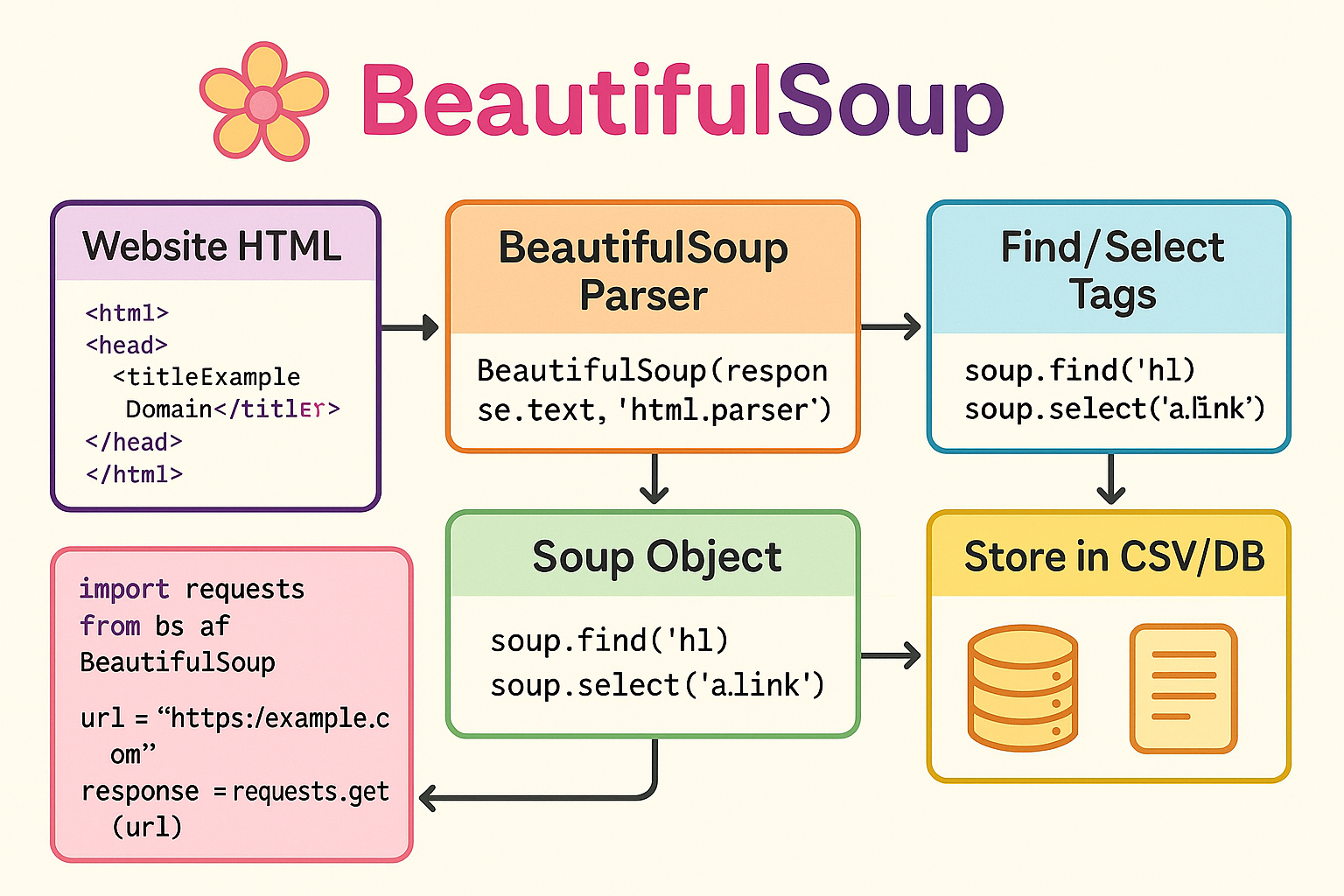
Website HTML → BeautifulSoup Parser → Soup Object → Find/Select Tags → Extract Data → Store in CSV/DB
❌ Can’t handle JavaScript-rendered websites (use Selenium or Playwright)
❌ Dependent on website structure (if website changes, scraper breaks)
❌ Too large pages may slow parsing
Always check robots.txt before scraping 🤖
Use time.sleep() to avoid overloading servers ⏳
Combine with pandas or CSV to store data 📊
For dynamic content, pair with Selenium / Playwright
✨ In short, BeautifulSoup is like a detective 🔍:
It reads a webpage’s HTML structure
Helps you search and extract data
Makes web scraping clean, easy, and pythonic 🐍
 Continue With Google
Continue With Google  Programming
Programming

